
Google's 'Frozen v2' Chip Bakes Gemini Into Silicon for 10x Efficiency
Google is reportedly building Frozen v2, a chip that hardwires Gemini into silicon for 6-10x more efficiency than its TPUs. The real story is inference economics.
Read post →Writing
Thoughts on AI, LLMs, shipping products, and the tools I use every day. RSS
Google is reportedly building Frozen v2, a chip that hardwires Gemini into silicon for 6-10x more efficiency than its TPUs. The real story is inference economics.
Read post →
xAI's Grok 4.5 hits Opus-class results with about four times fewer tokens. The real innovation in 2026 is doing the same job cheaper, not building bigger models.
Read post →
Microsoft is folding its Copilot apps into one and adding Autopilot, agents that run continuously without a prompt. The real story for builders is event-driven design.
Read post →
OpenAI shipped the GPT-5.6 series to everyone on July 9. It's three models, not one, plus a new ultra mode and predictable prompt caching that change how you build.
Read post →
The US pulled Anthropic's Fable 5 three days after launch and restored it 19 days later. The lesson for builders: never hard-depend on a single model.
Read post →
Anthropic made Sonnet 5 its default model with near-Opus 4.8 agent performance at a much lower price. The catch is a new tokenizer builders need to measure.
Read post →
Qualcomm is buying Modular for around 4 billion dollars. The target is not silicon, it is the software lock-in that keeps AI pinned to Nvidia.
Read post →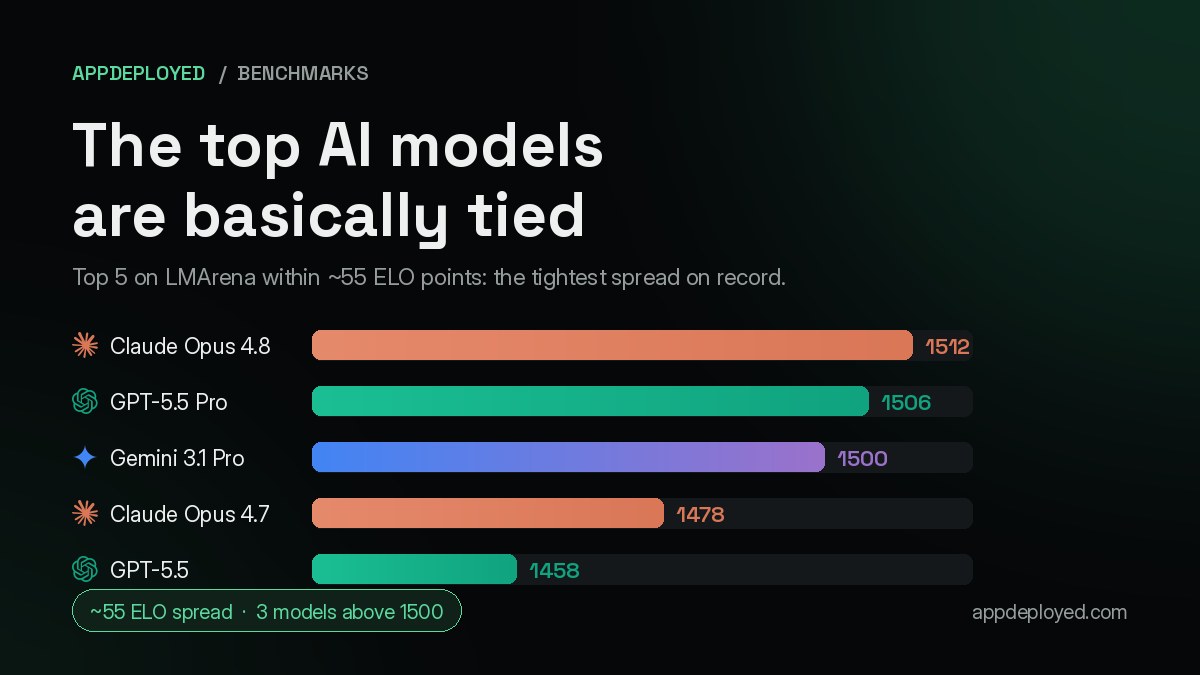
The top five models on LMArena sit within 55 ELO points, the tightest spread ever. Here is what that means for picking one.
Read post →
Deployment Simulation replays real traffic through a candidate model to forecast failures. Builders can copy the idea today.
Read post →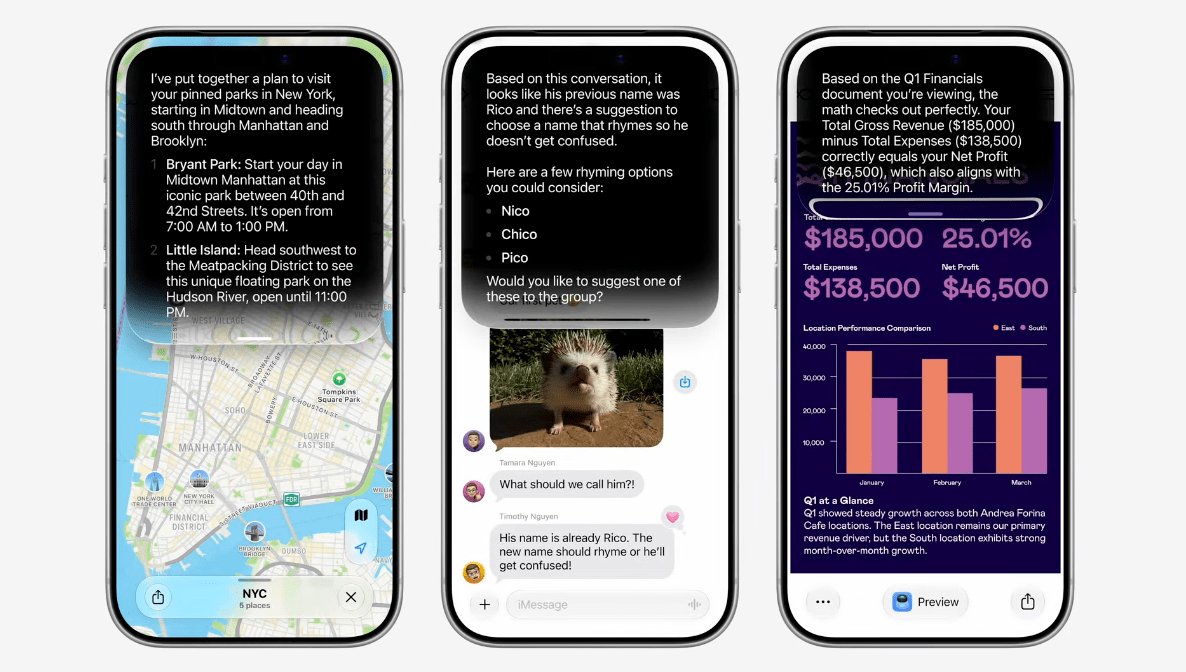
WWDC 2026 made the AI model a user setting. For builders, that quietly moves the moat up the stack.
Read post →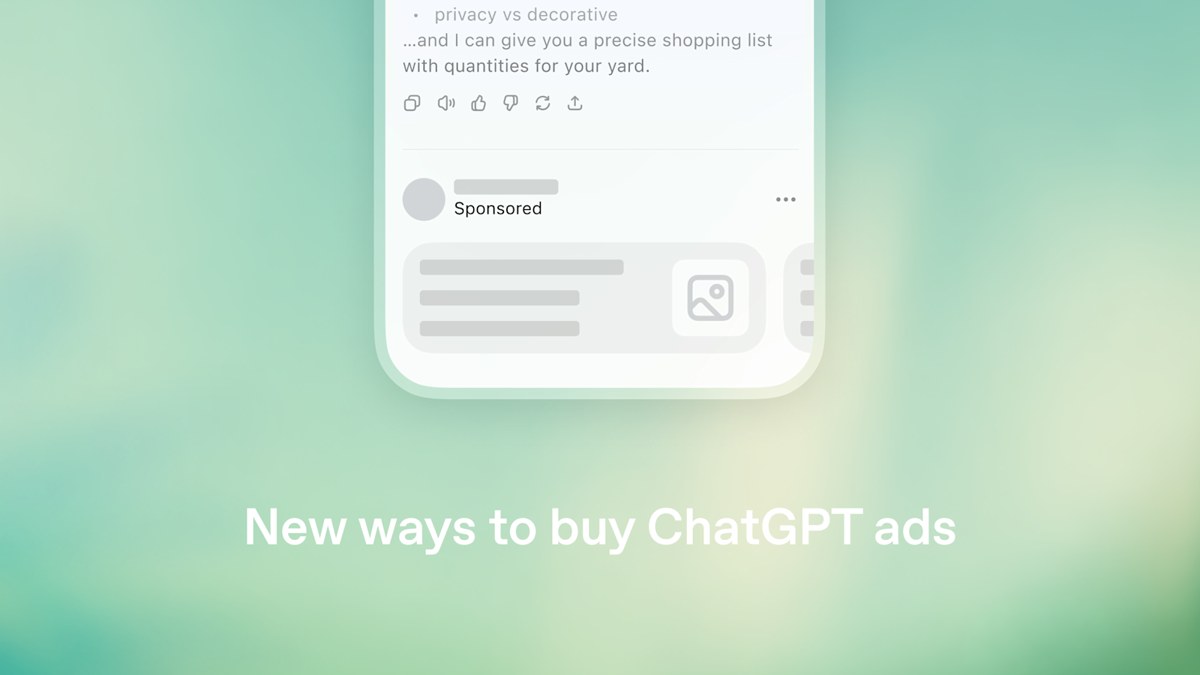
OpenAI opened a self-serve ads platform inside ChatGPT, with CPC bidding and conversion tracking. Here is the builder's read.
Read post →
OpenAI shipped three realtime audio models in one API. Here is why voice agents finally feel usable for builders.
Read post →
OpenAI's Dreaming V3 synthesizes memory in the background, no 'remember this' needed. Here is what it means for builders.
Read post →
Benchmarks tell you numbers. This post tells you what those numbers mean when you're actually building something.
Read post →
At Build 2026, Microsoft unveiled 7 in-house AI models including MAI-Thinking-1, a reasoning model trained without OpenAI or Anthropic data.
Read post →
An enterprise gave employees unlimited Claude access with no spending caps. The bill came in at $500M in 30 days. Here's exactly how it happened.
Read post →
Claude Code with Opus 4.8 can now orchestrate hundreds of subagents in one session — codebase-scale migrations, no manual handoffs.
Read post →
Nvidia's RTX Spark superchip runs 120B-parameter models locally, 1 petaflop of AI compute, 128GB RAM — in a slim Windows laptop this fall.
Read post →
Anthropic’s Opus 4.8 update adds effort controls and a faster mode, making it easier to trade cost, speed, and quality.
Read post →
Pope Leo XIV's first encyclical calls AI the defining challenge of our time and demands legal frameworks, not just ethics talk.
Read post →
Houston is a free desktop app that connects AI agents directly to your tools — so you stop being the copy-paste middleman.
Read post →
Google says AI Studio (powered by Antigravity) makes it easier to ship tiny apps fast, even if you don’t code daily.
Read post →
Early benchmarks on GPT-5.4 show 15–20% better multi-step tool use accuracy and stronger few-shot agent learning. Worth testing against your current stack.
Read post →
xAI completed training on Grok V9-Medium, a 1.5T-parameter model targeting coding and agentic tasks. Expected public release: mid-June 2026.
Read post →
Anthropic's Claude 4 family raises the bar on reasoning, tool use, and context length. Here's what changes for developers building AI-powered products.
Read post →
Most AI prototypes die in demo mode. Here's the decision framework I use to take a product from 'cool demo' to deployed — and what I've learned building Orion, the HBS Campus Guide, and other live apps.
Read post →
I've run both models through the same real-world tasks I use in production. Here's an honest comparison — not benchmarks, but what matters when you're shipping a product.
Read post →